How to Optimize for AI Search (AEO + GEO): The ARENA Framework
Search didn’t die. Distribution changed.
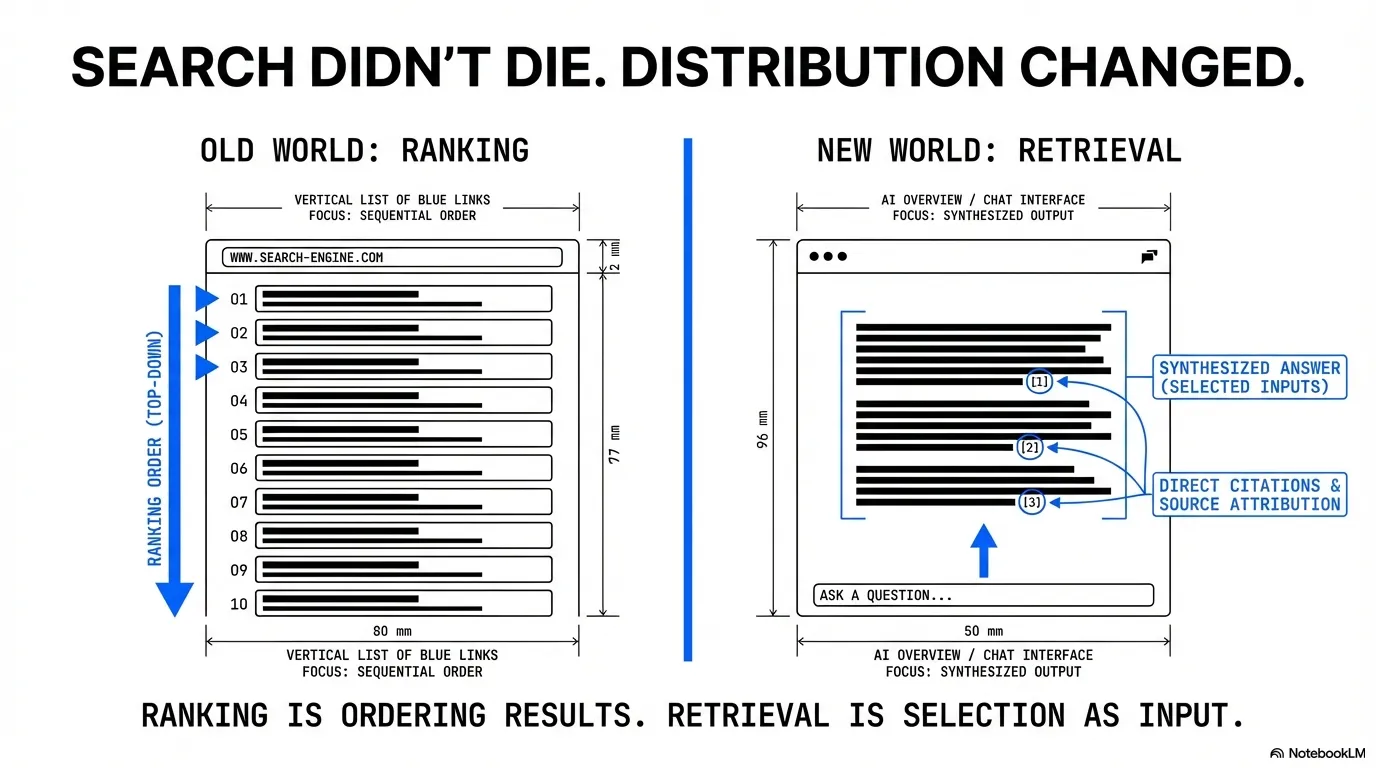
You can do everything “right” in SEO and still watch clicks fall, because the answer is getting assembled above the blue links.
That doesn’t make SEO irrelevant. It makes it incomplete.
If you want one definition to anchor the rest of this article, use this:
AI search optimization is the work of making your content retrievable and quoteable in AI-generated answers. The goal is to get cited accurately, and to have your brand attached to the claim.
What’s the Difference Between AEO and GEO?
AEO, GEO, LLMO, AISEO, and the new acronym flavor of the month.
The industry loves new labels. But AEO (Answer Engine Optimization) and GEO (Generative Engine Optimization) describe the same shift: optimizing for AI-generated answers, not just blue links.
Some people split hairs, but if you want to split it, it comes down to two questions: can the engine reuse your content accurately and cite it, and does the engine trust your brand enough to recommend it.
That’s also why you track AI authority signals separately. Mentions tell you you were seen. Citations tell you you were used. Read more about citation and mention differences.
In practice, the work is the same. This article calls it AI search optimization and moves on.
AI search shows up in a few places:
- Google AI Overviews
- Google AI Mode
- Chat engines (ChatGPT, Perplexity, Claude, Gemini, Copilot, Grok)
You’re optimizing for three outcomes:
- Being selected as a source
- Being mentioned as a recommendation
- Being quoted accurately, with your brand attached
If you can win those outcomes consistently, you’re not just getting visibility. You’re shaping what the engine believes is true about your category, and who it thinks deserves to be named. According to a Princeton/Georgia Tech study, GEO boosts visibility by up to 40% (source)
How Does AI Search Actually Work?
AI search is a retrieval and synthesis loop.
The AI answer system pulls sources from an index, selects passages that answer the question and the follow-up questions, then writes a new answer using those passages as grounding. If your page doesn’t get retrieved, you don’t exist. If your best passage can’t be lifted cleanly, you won’t be cited even when you rank.
A simple way to think about it:
- Retrieve candidate sources.
- Select passages that answer the question and the follow-up questions.
- Synthesize a response.
- Cite sources and, in some cases, recommend brands.
Most AI search guides turn this into a checklist. The problem is that checklists don’t explain why you win or lose. A pipeline does.
To operate this professionally, you need three evidence lanes:
- Classic ranking evidence (what ranks and how results are structured)
- Competitor coverage evidence (what they cover that you don’t)
- AI evidence (mentions and citations across AI surfaces)
What Is the ARENA Framework for AI Search?
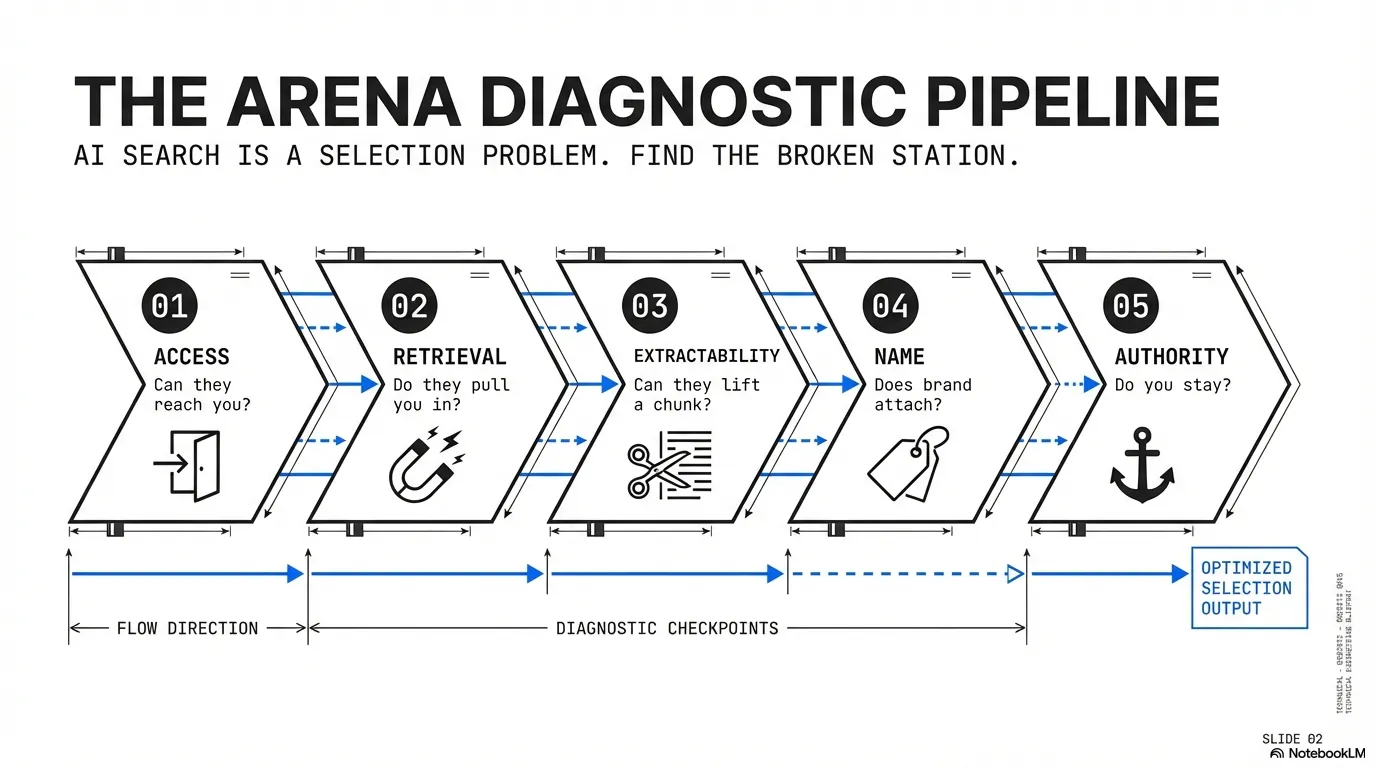
AI search optimization is a selection problem. Your content must have access, get retrieved as context, be lifted cleanly, have your name attached to the claim, and build authority so you keep showing up.
That’s the pipeline. If you can diagnose which step is failing, you can stop guessing and start fixing.
If you want a quotable version of the whole framework, it’s this: the ARENA Framework is how brands win AI answers. Access gets you into the system, retrieval gets you into context, extractability gets you quoted, name attaches your brand to the claim, and authority keeps you there as sources rotate.
Here’s how the AEO and GEO split maps to the work:
- AEO is about being understood and reused correctly (Access, Retrieval, Extractability)
- GEO is about being trusted enough to be recommended (Name, Authority)
| Label | What you are really trying to win | Mostly shows up in |
|---|---|---|
| AEO | being understood and reused correctly | Access, Retrieval, Extractability |
| GEO | being trusted enough to be recommended | Name, Authority |
The five ARENA steps:
- Access — can the system reach your page
- Retrieval — does your page get pulled into context
- Extractability — can the model lift a correct chunk
- Name — does your brand attach to the claim
- Authority — do you keep showing up as sources rotate
| Step | What it decides | What failure looks like |
|---|---|---|
| 1. Access (Eligibility) | Can the system access and use your page? | You never show up anywhere, no matter how good the article is |
| 2. Retrieval | Does your page get pulled into the context window? | You rank or exist, but you’re rarely cited |
| 3. Extractability | Can the model lift a correct chunk? | You get pulled, but someone else gets quoted |
| 4. Name (Attribution) | Does the brand attach to the claim? | Your idea appears, but your name doesn’t |
| 5. Authority (Reinforcement) | Do you keep showing up as sources rotate? | You show up for a month, then drift out |
ARENA is just a memory aid. The point is diagnosis.
If you treat AI search as a pipeline, you stop arguing about labels. You diagnose the bottleneck, and you fix the real constraint.
How Do You Diagnose Your AI Search Bottleneck?
You don’t need a new dashboard. You need a clean diagnosis.
Use this table to find the broken step fast:
- Never show up anywhere — Access problem
- Show up inconsistently — Retrieval problem
- Cited but the answer is wrong — Extractability problem
- Your ideas appear without your name — Attribution problem
- Used to show up but stopped — Authority problem
| Symptom | Likely Broken Step (ARENA) | What to Fix First |
|---|---|---|
| You never show up anywhere | Access (Eligibility) | crawl, rendering, indexation |
| You show up sometimes, but it’s inconsistent | Retrieval | retrieval assets and internal linking |
| Your page gets cited, but the answer is off | Extractability | quote blocks, constraints, caveats |
| Your ideas show up, but your brand doesn’t | Name (Attribution) | brand-to-claim binding near quote blocks |
| You used to show up, then disappeared | Authority (Reinforcement) | drift tracking and off-site corroboration |
This is the part most teams skip. It’s also the part that saves you months.
Step 1 (Access): Is Your Content Even Eligible for AI Search?
If you’re blocked, you’re invisible. Access is not strategy, it’s hygiene, and hygiene is where most teams quietly fail.
Access Checklist (Executive Summary)
Schema is not the point here, but it still matters. Properly structured content has 73% higher AI Overview selection rates (Wellows). It’s part of making your pages legible and your entities unambiguous, especially when the engine is stitching answers from snippets. Use it to clarify what a page is and who it belongs to, but don’t expect it to carry weak content.
Access still comes down to basics:
- Your pages are crawlable and not blocked by accident.
- Your content is visible without fragile client-side rendering.
- Your canonical and indexation signals aren’t self-sabotaging.
- You’re indexable across the ecosystems you rely on (Google and Bing at minimum).
See the full AI Search Access Checklist for the practitioner checklist.
Step 2 (Retrieval): Is Your Content Getting Retrieved?
This is where most SEO teams misunderstand the game. Ranking is about ordering results, but retrieval is about being selected as input. Overlap exists, but they’re not identical, and retrieval is usually about the sub-question, not the main keyword.
The Three Data Pathways AI Uses
Microsoft frames this for commerce, but the idea generalizes. AI systems don’t learn about you from one place, they triangulate.
AI systems learn about you through three pathways:
- Crawled pages: what the web says you are.
- Structured data and feeds: what you declare in machine-readable form.
- Live site experience: what the system sees when it actually visits.
If one pathway contradicts the others, you don’t look “wrong.” You look risky.
What Wins Retrieval
You win retrieval by making it obvious you’re the best source for the sub-question the engine is trying to answer.
Practically, that means building a small portfolio of “retrieval assets,” not just a pile of blog posts.
This is what a topical map is for.
A topical map is the blueprint of what your brand should own across a topic.
It combines brand strategy, buyer reality, and what the market already rewards into a hierarchy of pages and internal links. Questions are part of it, but they’re only one slice.
See what the best topical map software tools are.
Retrieval asset portfolio
Every brand needs four types of retrieval assets:
- Definition page — establishes the canonical explanation
- Comparison page — controls the tradeoff story
- Criteria page — provides decision rules
- Objection / FAQ page — handles skepticism
| Asset type | What it does | Example prompts it wins |
|---|---|---|
| Definition page | Establishes the canonical explanation | ”What is X?” “How does X work?” |
| Comparison page | Controls the tradeoff story | ”X vs Y” “best X for Y” |
| Criteria / process page | Provides decision rules | ”How to choose X” “What should I look for in X?” |
| Objection / FAQ page | Handles the skepticism | ”Is X worth it?” “Does X still work in 2026?” |
If you only publish “how-to” posts, you’re forcing the engine to assemble your viewpoint from fragments. That’s fragile.
If you publish retrieval assets, you become the cleanest input.
This is also why generic blogs get ignored. They don’t resolve sub-questions cleanly, so the engine finds a better chunk somewhere else.
See the full AI Search Retrieval Playbook for the retrieval asset portfolio, internal linking rules, and a quick retrieval test.
Step 3 (Extractability): Can AI Actually Quote Your Content?
AI systems lift chunks.
They reward passages that can be pasted into an answer with minimal editing.
Most teams think this is formatting. It’s not. It’s writing.
Information Gain Still Matters
You don’t win AI search by rewriting the top 10 results with different adjectives.
You win by adding something the engine can’t find everywhere else.
Examples of real information gain:
- A definition you can defend
- A framework with criteria, not vibes
- A decision table someone can actually use
- A constraint that prevents a common mistake
- A concrete example from practice
The Extractability Spec (What Your Writers Need)
- Answer-first paragraphs under every header.
- Self-contained sections that can stand alone.
- Lists and tables for multi-factor explanations.
- Constraints and caveats next to the claim, not buried later.
A simple test
If someone copied the first 120 words under each H2, it should still be correct.
If not, the model can’t safely quote you.
So it won’t.
Quote block example (before and after)
Here’s what a non-quoteable paragraph looks like:
Bad:
“AI search optimization is becoming more important as more answers move into AI surfaces. There are many strategies you can use to improve your visibility, such as creating high-quality content, building authority, and optimizing your pages. Over time, these efforts can help you show up more often.”
Here’s the same idea rewritten as a quote block:
Good:
“AI search optimization is the practice of making your content retrievable and quoteable in AI-generated answers. Retrieval gets you pulled in as context. Extractability gets your passage lifted. Authority keeps you showing up after sources rotate.”
See the full AI Search Extractability Spec for the 10-rule writer spec, anti-patterns, and QA checklist.
Step 4 (Name): Is Your Brand Attached to the Answer?
Getting cited is good.
Getting your ideas used without your name attached is how you build someone else’s moat.
That’s what attribution means here. Brand attachment.
Attribution is where founder-led content wins.
Not because founders are special.
Because founder-led content tends to have stable definitions, named frameworks, and consistent entity cues.
Most teams lose this because of context loss.
Brand and personas live in a doc nobody reopens, topic planning lives in a spreadsheet, and drafts drift. If you want name attachment, you need a system that keeps brand, audience, and topic strategy connected through execution.
Attribution Engineering (Executive Summary)
One practical test is simple. If a model quotes your idea, would a reader know it was you.
The basic moves:
- Bind your brand to your definitions once.
- Name your frameworks and keep names stable.
- Put a local attribution cue next to quote blocks.
- Make authorship real and consistent.
A simple example:
“This is the ARENA Framework we use at Floyi to diagnose why brands disappear from AI answers.”
See the full AI Search Attribution Engineering guide with copy templates.
Step 5 (Authority): Will You Still Show Up Next Month?
Most teams treat AI visibility as a launch.
They publish, check, celebrate, then disappear three weeks later.
That’s not a mystery. It’s drift.
Why Drift Happens
- New sources enter the corpus.
- Recency thresholds shift.
- Competitors publish cleaner quote blocks.
- Your own pages change and break their best chunks.
What Reinforcement Actually Means
Authority is corroboration. Not “PR for PR’s sake.”
It’s also stability. If you casually rewrite your best definitions and quote blocks, you break the chunks engines already learned to trust.
Authority is making your claims show up in enough trusted places that the system keeps seeing you as the safe source. This is where directories, lists, reviews, UGC, and third-party mentions matter.
Not as the whole strategy. As the stabilizer.
See the full AI Search Authority Reinforcement checklist for drift detection, refresh triggers, and the reinforcement playbook.
If you want to keep getting cited, treat reinforcement like maintenance, not marketing.
What Should You Do First to Improve AI Search Visibility?
Most teams try to “optimize everything” and end up shipping nothing.
A better approach is sequencing.
Fix access first so you’re eligible to be cited. In parallel, build a topical map so you know which retrieval assets you actually need. Then rewrite for extractability and brand attachment. Authority is what keeps it stable.
A simple 30/60/90 plan to improve AI Search visibility:
- First 30 days: fix access issues on the pages you want cited, and add quote blocks to the pages that already get impressions.
- Next 60 days: turn your topical map into retrieval assets (definitions, comparisons, criteria, objections) and tighten internal linking.
- Next 90 days: build authority (third-party corroboration) and start weekly drift tracking.
Which AI Surfaces Should You Optimize For?
The pipeline doesn’t change.
But the bottleneck often does.
Google AI Overviews (AIO)
AIO is the most important surface to understand because it sits on top of classic demand. Google Search is still where the majority of searchers go. AIO has even reduced position 1’s clickthrough rate by 58% (Ahrefs)
AIO tends to reward:
- clean definitions
- list-friendly formatting
- corroborated facts (stats, benchmarks, transparent criteria)
Google AI Mode
AI Mode is not “AIO but bigger.” It behaves differently, expands into sub-questions, and can draw from a different mix of sources. According to an Ahrefs study, there’s only a 13.7% citation overlap between AI Mode and AIO (source)
Treat it as its own surface.
The practical implication is that you’re optimizing for coverage across sub-questions, not one perfect paragraph.
A simple way to remember the difference:
| Surface | Typical behavior | What to optimize for |
|---|---|---|
| AI Overviews | compresses one query into a summary | clean definitions and quotable blocks |
| AI Mode | fans out into many sub-questions | coverage across a topic, not just one page |
Read more about query fan-out.
ChatGPT
ChatGPT is a different ecosystem.
Different retrieval sources, different behavior, different citation patterns.
You still win with:
- access
- retrieval assets
- extractable chunks
- authority
The Rest (Touch, Don’t Deep-Dive)
| Surface | Why it matters | What to do first |
|---|---|---|
| Gemini | Google’s LLM surface outside classic search | Same pipeline, prioritize access + extractability |
| Perplexity | Research-first answer engine with citations | Build retrieval assets + quote blocks |
| Claude | Often used by tech pros; different sourcing | Authority + strong definitions |
| Bing Copilot | Bing ecosystem exposure | Bing indexation + comparison assets |
| Grok | Fast-moving, social-adjacent | Authority and brand clarity |
How Do You Measure AI Search Visibility?
If your dashboard is still “rankings + clicks,” you’re managing the wrong system.
AI search visibility is not one number. It’s whether you are cited, whether you are recommended, whether you are represented accurately, and whether you are gaining share against competitors.
You need a weekly cadence that answers:
- whether we are being cited
- whether we are being represented accurately
- whether we are gaining share versus competitors
- where the pipeline is breaking
The Weekly Visibility Report
Track:
- prompt sets by intent cluster
- citation frequency + URLs
- brand representation accuracy score
- competitor co-mentions
A starter prompt set helps teams move faster.
Pick 10 prompts that match how buyers and prospects ask questions:
”What is {category}?””{category} vs {alternative}””Best {category} for {use case}””How do I choose {category}?””Does {category} still work in 2026?””Common mistakes with {category}””Is {category} worth it?””What are the limitations of {category}?””How long does it take to implement {category}?””What’s an example of {category} done well?”
See the full AI Search Visibility Measurement Template for the weekly reporting template.
Who Owns What
| Workstream (ARENA) | Owner | What they ship |
|---|---|---|
| Access (Eligibility) | Engineering + SEO | crawl/index readiness across ecosystems |
| Retrieval | Content strategy + SEO | retrieval asset portfolio + internal linking |
| Extractability | Editorial | quoteable passage quality |
| Name (Attribution) | Founder/editorial + SEO | brand-to-claim binding + authorship integrity |
| Authority (Reinforcement) | Founder/marketing/PR | corroboration and durability |
If you don’t assign owners, you don’t have a strategy. You have a hope.
The Real Takeaway
Stop asking whether it’s AEO or GEO.
Ask where your pipeline is breaking. Because in AI search, the winner isn’t the brand with the most content.
It’s the brand with the cleanest retrieval assets, the most quoteable passages, and the strongest reinforcement.
If you want to run this as a system, Floyi connects topical maps, briefs, and AI visibility tracking into one loop.
Practitioner Kit
Each ARENA step has a dedicated checklist, spec, or template. The pillar article above teaches the framework. These pages give your team the tools to execute it.
Not sure which step is breaking? Start with the one-page ARENA diagnostic to find your bottleneck in 5 minutes.
Access Checklist
Crawl access, rendering, indexation, and validation. If your pages aren’t eligible, nothing else matters.
- Make sure pages are crawlable and not blocked by accident
- Validate rendering, canonicals, and indexation across Google and Bing
- Run prompt-based surface checks to confirm eligibility
Retrieval Playbook
Build the pages AI systems actually pull into context, not just blog posts that rank.
- Build four types of retrieval assets: definition, comparison, criteria, objection
- Use internal linking to express topic hierarchy
- Test retrieval with a weekly prompt set
Extractability Spec
A 10-rule writing spec for making your content quoteable in AI-generated answers.
- Start each section with the answer
- Write self-contained passages that work when copied alone
- Add quote blocks, constraints, and caveats next to claims
Attribution Engineering
How to get your brand attached to the claim, not just cited as “a source.”
- Bind your brand to key definitions once
- Name your frameworks and keep names stable
- Place attribution cues next to quoteable passages
Authority Reinforcement
Keep showing up as sources rotate. Drift detection, refresh triggers, and off-site corroboration.
- Track the same prompt set weekly
- Protect your best quote blocks and keep definitions stable
- Build off-site reinforcement so you don’t fade out
Visibility Measurement Template
A weekly reporting template for tracking mentions, citations, accuracy, and drift across AI surfaces.
- Define prompt sets by intent cluster
- Score accuracy and track competitor co-mentions
- Turn weekly data into next actions by ARENA step